Establecer la cuenta de un Organizational Browser
Debo de admitir que SharePoint tiene algunos controles y WebParts que son muy padres y que de hecho son muy útiles. Algunos, como los que están clasificados bajo «Social y colaboración», son muy llamativos para los usuarios. De hecho, uno que vale la pena mencionar es el Organizational Browser.
Si no lo conoces, te comento que este WebPart crea un navegador de jerarquías de empleados, es decir, un organigrama. Comienzas con tu cuenta de usuario y te aparece en la parte superior la jerarquía de jefes hasta llegar al nivel más alto (presumiblemente un CEO). Hacia abajo, muestra a tu equipo de trabajo: quiénes te reportan directamente. Y hacia los lados están tus colegas: aquéllos quienes reportan al mismo jefe que tú.
Pero no solo es mostrar una estructura determinada, sino que al dar clic en cada persona (ya sea jefe, tu equipo o tus colegas) ésta pasa al centro y se muestra su propia estructura: jefes, colegas y equipo. Así, puedes navegar por toda la estructura organizacional de la empresa (claro, siempre y cuando el Directorio Activo esté sano).
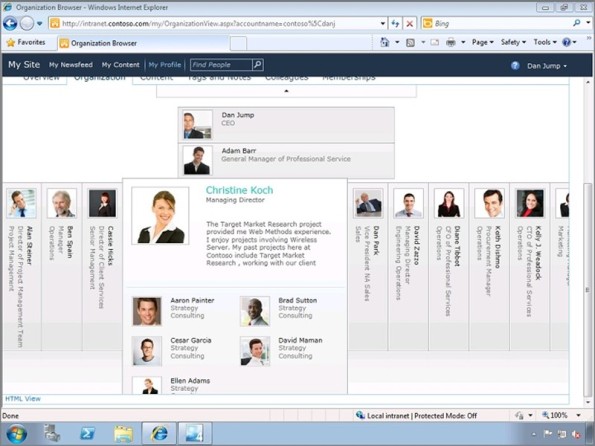
Si tu granja tiene habilitado el My Site, entonces ya cuentas con una página en tu perfil donde se muestra este control. Si no, puedes agregar el control en cualquier página mediante el WebPart llamado Organizational Browser localizado en la categoría de Social Collaboration.
La capacidad de contar con un organigrama cuando creamos Team Sites dentro de SharePoint es fundamental, y muchas veces ignorada. Considera un Team Site para dar soporte sobre un servicio X dentro de la organización. Tener el organigrama disponible permite ver con quién dirigirse para tratar un tema determinado, o con quién realizar una escalación. Asimismo, para los miembros del equipo, nos pone a la mano la información de contacto: teléfonos, correos, direcciones, etc.
Por todos los bienes que trae este control, cuenta sin embargo con una gran deficiencia. Cuando añadimos el WebPart, éste siempre va a renderizar el organigrama a partir de la cuenta que ha ingresado. Es decir, siempre mostrará tu cuenta. Este es, a mi juicio, un error de funcionalidad. Si bien es cierto que este comportamiento es deseable dentro del My Site, debería dar la capacidad de configurar la cuenta de inicio de forma sencilla. Esto es lógico: si creamos un Team Site para el área de finanzas, seguramente querremos que el organigrama se despliegue con el CFO (Chief Financial Officer, o director de finanzas) en el centro. Y esto es algo que los tíos del SharePoint Development Team no nos dejaron hacer, al menos de forma sencilla: editar
Al respecto, estuve investigando formas para trabajar alrededor de esto. Hay varias ideas al respecto, la mayoría sugieren crear una página ASPX y empotrar un par de controles: un ProfilePropertyLoader y un ProfileBrowser. En este hilo dentro de los foros de MSDN es lo que sugieren, con este código.
<%@ Page language=»C#» … otras declaraciones de ASP.NET… %>
<asp:Content contentplaceholderid=»PlaceHolderAdditionalPageHead» runat=»server»>
</asp:Content>
<asp:Content contentplaceholderid=»PlaceHolderMain» runat=»server»>
<SPSWC:ProfilePropertyLoader id=»m_objLoader» LoadFullProfileOfCurrentUser=»true» runat=»server» />
<div class=»orgBrowser»>
<SPSWC:ProfileBrowser ChromeType=»None» runat=»server» __WebPartId=»{553DA676-D81E-4B0B-B8FA-58518A90C5D8}» />
</div>
</asp:Content>
Según esto, con invocar al ASPX pasándole como parámetro por el Query String un accountname=midominio\micuente es suficiente. De hecho, encontré varios foros y blogs donde sugieren este mismo enfoque. Sin embargo, plantea un problema: se requiere del SharePoint Designer para poder editar los ASPX de esta forma. Y en muchos casos las granjas corporativas bloquean por seguridad el uso de esta herramienta. De hecho, mi granja sufre de esto mismo.
Así las cosas, estuve buscando alternativas para solventar este problema. Dado que no encontré una, me decidí por investigar el control a fondo. Una rápida examinada al código HTML generado por una página que contenga este control indica que en realidad es un control de Silverlight, y que el WebPart no es más que un envoltorio que lo invoca. El objeto en cuestión se localiza en la url ‘/_layouts/ClientBin/hierarchychart.xap’.
Ahora bien, tras descargar dicho XAP, cambiarle la extensión por ZIP, y descomprimir el archivo, tuve acceso a HierarchyChart.dll. Tras abrirlo con algún desensamblador (yo usé el integrado de SharpDevelop) y explorar las clases, pude ver que en realidad el control toma el parámetro llamado initialParameters, y espera que éste sea una cadena de texto con los parámetros separados por coma. En particular, espera que el primer parámetro sea el Profile ID, es decir, el dominio + cuenta del usuario inicial que el control habrá de renderizar; y el segundo parámetro el tipo de usuario, usualmente UserType.
Mi reacción ante este hallazgo fue de gusto: entonces la solución sería crear un WebPart de tipo Silverlight Content, apuntar al XAP en cuestión, y en los parámetros iniciales (que sí pueden editarse desde el propio WebPart) poner mi cuenta, seguido del UserType separado por comas. Sin embargo, al probar esto no me funcionó. Tras revisar, resulta que nuestro buen WebPart Silverlight Content añade la URL a los initialParameters que configuramos, y por tanto el control de Silverlight nunca leería bien el ID de cuenta, pues estaría leyendo la URL.
Este hecho me frustró y obligó a cambiar de enfoque. Regresé a revisar el código generado por el Organizational Browser, con mayor detenimiento, y me topé que en realidad el WebPart no genera el enlace hacia el XAP, sino que hay un JavaScript que crea dinámicamente el control Silverlight. El pedazo de código más importante se encuentra en la función CreateHierarchyChartControl, cuyo extracto reproduzco a continuación.
function CreateHierarchyChartControl(parentId, profileId, type, persistControlId)
{
var initParam = profileId + ‘,’ + type + ‘,’ + persistControlId;
var host = document.getElementById(parentId);
host.setAttribute(‘width’, ‘100%’);
host.setAttribute(‘height’, ‘100%’);
Silverlight.createObject(
‘/_layouts/ClientBin/hierarchychart.xap’,
host,
‘ProfileBrowserSilverlightControl’,
{
top: ’30’,
width: ‘100%’,
height: ‘100%’,
version: ‘2.0’,
isWindowless: ‘true’,
enableHtmlAccess: ‘true’
},
{
onLoad: OnHierarchyChartLoaded
},
initParam,
null);
}
Como puedes ver, esta función crea el objeto XAP y le pasa los parámetros iniciales. La función toma como segundo parámetro un profileId, que es de hecho la cuenta (dominio\cuenta) inicial del Organizational Browser. Así, si de alguna forma pudiéramos invocar la función con el parámetro cambiado… pero intentar hacerlo resulto un completo dolor en el cu…erpo, puesto que hay muchas otras funciones involucradas.
Tras explorar el código, recordé sin embargo una característica interesante de JavaScript, más bien oscura. Toma este ejemplo.
<script type=»text/javascript»>
function foo() {
alert(‘Foo 1’);
}
function foo() {
alert(‘Foo 2’);
}
foo();
</script>
Al ejecutarse, ¿qué pasará con este script? Evidentemente tenemos definida la función un par de veces. Sin embargo, no ocurre un error. Lo que sucede aquí al ejecutarse es que se muestra una alerta con el texto Foo 2. Esto se debe a una característica de JavaScript: cuando dos funciones con la misma firma y nombre son declaradas, el compilador / intérprete deberá tomar en cuenta la definición más reciente (es decir, la última). ¡Con esto ya tenemos la solución, y ni siquiera tenemos que usar el SharePoint designer! En efecto, lo que tendríamos que hacer es crear una segunda función llamada CreateHierarchyChartControl y añadir los initParams que queremos.
Vamos paso a paso.
1.- Crear una página que permita añadir WebParts, ya sea a un WebPartZone o a un RichContent.
2.- Editar la página y añadir un Organizational Browser WebPart.
3.- Abajo del WebPart anterior (y es importantísimo que sea abajo) añadir un Content Editor WebPart (localizado en la categoría Media and Content.
4.- Seleccionar nuestro Content Editor WebPart y en las propiedades de WebPart, hacer clic en editar.
5.- Colocar el cursor en el espacio vacío del Content Editor WebPart y se habilita la cinta contextual (Ribbon) de Format Text. En el panel Markup, seleccionar la opción Edit HTML Source.
6.- En el panel HTML Source que aparece, añadir este código y guardar
<script type=»text/javascript»>
function CreateHierarchyChartControl(parentId, profileId, type, persistControlId)
{
//var initParam = profileId + ‘,’ + type + ‘,’ + persistControlId;
var initParam = ‘midominio\\micuenta,’ + type + ‘,’ + persistControlId; // editar
var host = document.getElementById(parentId);
host.setAttribute(‘width’, ‘100%’);
host.setAttribute(‘height’, ‘100%’);
Silverlight.createObject(
‘/_layouts/ClientBin/hierarchychart.xap’,
host,
‘ProfileBrowserSilverlightControl’,
{
top: ’30’,
width: ‘100%’,
height: ‘100%’,
version: ‘2.0’,
isWindowless: ‘true’,
enableHtmlAccess: ‘true’
},
{
onLoad: OnHierarchyChartLoaded
},
initParam,
null);
}
</script>
7.- En la segunda línea de la función, donde está el comentario «// editar», hay que cambiar «midominio\\micuenta» por el dominio/cuenta del usuario que deba mostrar por vez primera el Organizational Browser. Nota que la diagonal invertida tiene que escaparse, de ahí que sean dos.
8.- Guardar la edición de la página con todos sus cambios, y regenerar la página.
¿Sí notaste lo que hicimos? El Content Editor WebPart añade una función que se llama CreateHierarchyChartControl. Como pusimos el WebPart después que el Organizational Browser, esta segunda función será la que el Organizational Browser ejecute en lugar de la normal, debido a que JavaScript siempre tomará como válida la última. Y en nuestra función JavaScript, armamos el initParameters a nuestro gusto, hardcodeando en este caso la cuenta (en tu caso, puedes leer desde query string o algún otro lado, si no te gusta hacer un hardcode).
La siguiente imagen muestra cómo quedó mi sitio.
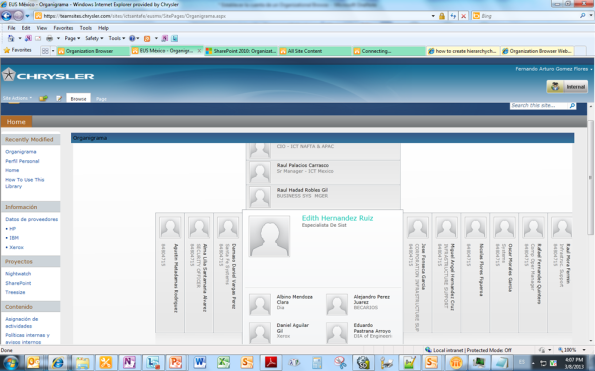
Por favor, no dejes de enviar comentarios con sugerencias para monitorear si esta solución es escalable o presenta algún problema raro. En mi caso funcionó súper bien, pero ya ves que luego esto puede variar: your mileage may vary, dirían en EE.UU.
Eso es todo amigos.
C# 101: cadenas de texto
Las cadenas de texto representan al tipo de dato más importante en un lenguaje, tras el tipo de dato número entero. En efecto, toda la información (al final el propósito de un programa informático es manipular información) consiste principalmente en cadenas de texto. Una gran parte al menos. Así, manipular las cadenas de texto se vuelve esencial en cualquier lenguaje.
Si uno compara plataformas antiguas con plataformas modernas como Java y .NET, podemos encontrar diferencias significativas. Probablemente la mayor de éstas sea que hoy en día las cadenas de texto son inmutables. Esto quiere decir que una cadena de texto que se crea ya no puede cambiarse. Puede, en cambio, crear nuevas cadenas a partir de una. En fin, poco a poco.
¿Qué es una cadena de texto?
Una cadena de texto es una colección secuencial de caracteres, los cuales forman palabras y demás tipo de información. Cada carácter es en realidad un carácter en formato Unicode.
La clase que representa a una cadena de texto es System.String, y la que representa un carácter, es System.Char. El operador " " representa una cadena de texto constante, y por tanto puede asignarse directamente a una cadena de texto. El operador ‘ ‘ representa un carácter, y por tanto puede asignarse a una variable apropiada.
string str = "Hola mundo";
char ch = 'H';
char[] chs = new char[] { ch, 'o', 'l', 'a', ' ', 'm', 'u', 'n', 'd', 'o' };
La clase string tiene un método, llamado Empty, que representa una cadena de texto vacía. Equivale a colocar la constante "".
string str = string.Empty; str = "";
La clase string puede inicializarse de varias formas:
// operador " "
string s1 = "Hola mundo";
// mediante el constructor
string s2 = new strnig("Hola mundo");
// a partir de un array de caracteres
string s3 = new string(
new char[] { 'H', 'o', 'l', 'a', ' ', 'm', 'u', 'n', 'd', 'o' });
// a partir de un carácter que se repite n veces
string s4 = new string('*', 10); // **********
// a partir de un grupo de bytes con signo
sbyte[] bytes = { 0x41, 0x42, 0x43, 0x44, 0x45, 0x00 };
unsafe {
sbyte* p = bytes;
string s5 = new string(p);
}
Los caracteres son una estructura, por tanto son tipos valor (ValueType). Las cadenas de texto son clases, y por tanto son tipos referencia.
¿Qué es eso de Unicode?
Unicode es el nombre del formato en el que se presenta una cadena de texto en .NET. Un byte con signo (8 bits) puede almacenar números del -127 al 128. Los 128 números son suficientes para representar toda la tabla de caracteres ASCII. Así, por ejemplo, el número 64 equivale a una A, el 65 a una B, etc. Así nació la primera tabla de caracteres.
Después a alguien se le ocurrió que podía utilizarse un byte sin signo (8 bits), el cual puede almacenar números del 0 al 255. Con esto podemos almacenar más caracteres, y se creó la tabla ASCII extendida. 255 caracteres son muchos. Las letras acentuadas, por ejemplo, forman de ASCII extendido. Prácticamente se incluyeron todas las letras, caracteres y símbolos del alfabeto latino.
Sin embargo, a pesar de ello, ASCII+ es insuficiente todavía para guardar todos los caracteres de otros lenguajes, como el chino mandarín, la escritura hebrea, griega, cirílica, etc. Así, en los 90s se propuso un formato, llamado Unicode, el cual considera caracteres de dos bytes sin signo (16 bits), los cuales pueden almacenar números del 0 al 65536. Ahora, con 65536 caracteres sí que caben los chinos, los sánscritos y hasta el élfico antiguo de Lord of the Rings. Hay otro formato, Unicode 32 (de 4 bytes sin signo), pero la verdad es que no se utiliza mucho. El bueno, estándar, es el Unicode, al menos para .NET.
¿Eso quiere decir que cada carácter me cuesta 2 bytes de memoria?
Así es. La cadena de texto "Hola mundo" te cuesta 20 bytes. Esto implica, por supuesto, que mucho texto puede salirte caro en términos de memoria. El tamaño máximo de una cadena de texto en .NET es de 2 GB, o 1,073,741,824 caracteres.
Hay que tener cuidado, al final las cadenas de texto pueden ser potencialmente grandes, así que ten cuidado nada más.
¿Y qué es eso de que son inmutables?
Ah, eso quiere decir que una cadena de texto no cambia, una vez que le has asignado un valor. Es como si el valor en memoria fuera de solo lectura. Por supuesto que internamente no es así, pero la clase string no expone ni un solo método o propiedad que modifique el contenido. Todos los métodos operan sobre el valor del objeto actual, pero construyen uno nuevo, que es lo que devuelven.
La decisión de hacerlo de esta forma viene por razones históricas. Si uno programa para Win32 con C o C++, recordará que en estas plataformas las cadenas de texto pueden o no ser mutables. Por un lado, tenemos las cadenas estáticas o array de caracteres que no cambian su tamaño. Pueden ser declaradas en la pila de memoria o en el montículo de memoria. Si se declara en el montículo, entonces la cadena puede cambiar de tamaño. Desde el punto de vista de una función, el parámetro que recibe no sabe si es una cadena fija o dinámica.
void SetWindowText(HWND hWnd, LPCTSTR lpszText) // LPCTSTR == const TCHAR*
{
…
}
TCHAR sz[20] = L"Hola mundo!"; // cadena fija
TCHAR* psz = new TCHAR[20];
wcscpy(psz, L"Hola mundo!");
// indistinguible para SetWindowText
SetWindowText(sz);
SetWindowText(psz);
delete [] psz;
Y peor aún es cuando una cadena de texto tiene que ser creada y devuelta por una función. En ese caso pides la cadena en referencia más el tamaño de la misma. O bien, regresas una cadena dinámicamente creada y esperas que el programador no se olvide de liberar la memoria antes de salir. Ah, y si tu cadena permite tener nulos intermedios, entonces tienes que usar otros métodos.
Por esta misma complicación, salieron muchas muchas muchas clases y opciones para paliar el dolor. De entrada, Win32 define CHAR, WCHAR y TCHAR, con sus equivalentes punteros: LPSTR, LPWSTR y LPTSTR, más sus constantes LPCSTR, LPCWSTR, LPCTSTR. El Microsoft Foundation Classes, MFC, tiene la clase CString, y el Active Template Library, ATL, (junto con Windows Template Library, WTL) define su propia clase CStringT. Ah, y el estándar de C++ define std::string y std::wstring, que heredan de std::basic_string<T>. Por ahí el Component Object Model define BSTR, con varios métodos como SysAllocString y SysFreeString, más la clase _bstr_t y CComStr.
En fin, con tanto relajo, la gente que ideó C# y .NET debía tomar una decisión sobre cómo manejar cadenas en .NET, para evitar caer en el relajo que se tenía. Tanto cadenas estáticas como dinámicas presentan ventajas y desventajas. Las estáticas provocan algoritmos complejos para crear nuevas cadenas de texto, pero son seguras. Las dinámicas son inherentemente inseguras pero pueden crecer a conveniencia. Al final, la decisión fue que las cadenas iban a ser dinámicas (i.e. referencias) PERO sólo internamente: la clase que las representa no expondría ningún método para que un programador pudiera cambiar su valor interno. De esta forma se aseguraban lo mejor de los dos mundos: dinamismo pero a su vez, inmutabilidad. Incluso gracias a eso pudieron diseñar algunos algoritmos para optimizar su manejo.
Ok, entiendo el dilema, pero si son inmutables, ¿cómo podemos realizar operaciones para crear nuevas cadenas?
Las operaciones que pueden realizarse sobre cadenas de texto son variadas: concatenación, substitución de bloques de texto, búsquedas, indización, reemplazo de caracteres, formateo, conversiones, etc. Todas estas operaciones en realidad devuelven una nueva cadena de texto, basada en la cadena actual más la operación en cuestión. Pero la cadena actual nunca se ve afectada.
Pongamos como ejemplo el reemplazo de un bloque de texto. El método String.Replace toma dos parámetros: una cadena que representa el valor que queremos buscar, y otra cadena que representa el valor con el que reemplazaremos a la primera. El método opera sobre una cadena determinada, y regresa otra cadena con el valor modificado.
string strorg = "Todos los perros van al cielo";
string strmod = strorg.Replace("perros", "pollos");
Console.WriteLine("Cadena original: {0}", strorg);
Console.WriteLine("Cadena nueva: {0}", strmod);
/* imprime:
Todos los perros van al cielo
Todos los pollos van al cielo
*/
Vemos que aunque aplicamos el método Replace sobre strorg, éste no modifico su valor, sino que creó una nueva cadena con la operación aplicada, la cual regresó.
Momento: ¿no significa eso que entonces que estamos creando muchas instancias de cadenas?
En efecto. Hay que tener mucho cuidado, es muy importante estar conscientes de esto. En particular, la concatenación de cadenas de texto es particularmente cara en cuanto a recursos.
int i = 42; int n = 9; int m = 6; string s = "Según la guía interestelar, " + i + " es la respuesta última a la " + "vida, el universo y todo lo demás, siendo la pregunta: ¿cuánto es " + n + " por " + m + "? ";
El operador + está sobrecargado para precisamente concatenar dos valores. Si uno de los valores no es una cadena de texto, se le convierte en cadena en automático, bien mediante una conversión directa, bien mediante el método ToString. Así las cosas, veamos las cadenas que se han creado.
|
Expresión |
Cadena |
|
Estática |
Según la guía interestelar, |
|
i.ToString() |
42 |
|
Concatenación |
Según la guía interestelar, 42 |
|
Estática |
es la respuesta última a la |
|
Concatenación |
Según la guía interestelar, 42 es la respuesta última a la |
|
Estática |
vida, el universo yo todo lo demás, siendo la pregunta: ¿cuánto es |
|
Concatenación |
Según la guía interestelar, 42 es la respuesta última a la vida, el universo y todo lo demás, siendo la pregunta: ¿cuánto es |
|
n.ToString() |
9 |
|
Concatenación |
Según la guía interestelar, 42 es la respuesta última a la vida, el universo y todo lo demás, siendo la pregunta: ¿cuánto es 9 |
|
Estática |
por |
|
Concatenación |
Según la guía interestelar, 42 es la respuesta última a la vida, el universo y todo lo demás, siendo la pregunta: ¿cuánto es 9 por |
|
m.ToString() |
6 |
|
Concatenación |
Según la guía interestelar, 42 es la respuesta última a la vida, el universo y todo lo demás, siendo la pregunta: ¿cuánto es 9 por 6 |
|
Estática |
? |
|
Concatenación |
Según la guía interestelar, 42 es la respuesta última a la vida, el universo y todo lo demás, siendo la pregunta: ¿cuánto es 9 por 6? |
Perdonen la expresión, pero ¡en la madre! Quince cadenas se han creado, y se duplican muchísimos valores. ¡De entrada todas las cadenas "Concatenación" deberían ahorrarse, no hacen sentido! Y ahora se me caen los calzones: 1738 bytes por 869 caracteres, es decir 1.7 KB. La cadena original que queríamos formar, al final, fue de 266 bytes por 133 caracteres. Es decir que para formar una cadena de 266 bytes tuvimos que gastarnos 1472 bytes: 553% más de consumo de memoria.
Desafortunadamente, es la desventaja (o "trade-off") que tenemos que dar por poder manejar este modelo de cadenas de texto inmutables. La lógica detrás de esto es que es mejor tener un sistema más ineficiente a propiciar excepciones y errores de programación en las aplicaciones. Pero eso no nos exime de problemas ulteriores. He visto sistemas (sobre todo aplicaciones web hechas con ASP.NET) donde la aplicación está muy lenta, consume muchos recursos o de plano muere por falta de memoria, precisamente por tener un muy mal manejo de cadenas de texto.
¿Entonces no hay esperanza? ¿No podremos escribir aplicaciones intensivas en texto?
Depende mucho del programador. Una concatenación como la anterior causará muchos problemas, sobre todo cuando ésta se repite mucho. Y eso depende del programador, depende de ti.
Sin embargo, vale la pena aclarar, por si hubo alguna confusión: las cadenas son inmutables para los clientes de la clase String, es decir, para nosotros simples programadores mortales. Otras clases amigas (internas en C#) sí que pueden tener acceso a los miembros que permitan modificar la cadena de texto.
¿Eso quiere decir que hay clases especiales para ayudarnos?
Precisamente. .NET pone a nuestra disposición varias clases que nos ayudan muchísimo con la gestión de recursos de texto. Estas clases, en particular, hacen uso de estos principios:
1.- uso dinámico de la cadena de texto, ampliando y reduciendo su tamaño, pero protegido.
2.- creación de búferes lo suficientemente grandes para no estar redimensionando la cadena en cada momento, pero no tanto que consuma demasiada memoria.
3.- preferir el movimiento de los bytes de una cadena en lugar de copiarlos.
Esto disminuye significativamente la creación de las cadenas y por tanto el consumo de memoria. Un método de la clase String: String.Format, nos ayuda también con esto. Veamos:
int i = 42;
int n = 9;
int m = 6;
string s = string.Format("Según la guía interestelar, {0} es la respuesta última
a la vida, el universo y todo lo demás, siendo la
pregunta: ¿cuánto es {1} por {2}?", i, n, m);
Este código genera las siguientes cadenas:
|
Expresión |
Cadena |
|
Estática |
Según la guía interestelar, {0} es la respuesta última a la vida, el universo y todo lo demás, siendo la pregunta: ¿cuánto es {1} por {2}? |
|
i.ToString() |
42 |
|
n.ToString() |
9 |
|
m.ToString() |
6 |
|
Formateo |
Según la guía interestelar, 42 es la respuesta última a la vida, el universo y todo lo demás, siendo la pregunta: ¿cuánto es 9 por 6? |
String.Format hace uso internamente de otra clase, que veremos más adelante, y que se adhiere a los tres principios expuestos anteriormente. En este caso, creamos 275 caracteres, lo cual representa 550 bytes. Esto representa un 37% de los bytes empleados al usar la concatenación del ejemplo anterior. Es decir, nos ahorramos un 63% de memoria. Una diferencia significativa.
String.Format parece adecuado para cadenas pequeñas, pero ¿qué pasa con las grandes cadenas?
En estos casos tienes unas cuantas opciones. La primera, más fácil y más obvia, es utilizar la clase StringBuilder. Esta clase construye cadenas de forma eficiente, y de hecho el método String.Format utiliza internamente un StringBuilder.
Básicamente, StringBuilder mantiene su propio búfer, y cuando se hace alguna operación sobre el texto que cambie la longitud de la cadena, la clase revisa si tiene suficiente tamaño en su búfer, y si no, el tamaño del búfer es incrementado en un tamaño determinado. Durante todo este tiempo, ¡StringBuilder NO utiliza ningún string! Sino que guarda todo a nivel de bytes. Sólo hasta que se invoca al método StringBuilder.ToString es que la clase construye el string.
Nuestro ejemplo anterior se vería así, utilizando StringBuilder.
StringBuilder text = new StringBuilder()
.Append("Según la guía interestelar, ")
.Append(i)
.Append(" es la respuesta última a la vida, el universo y todo lo demás,
siendo la pregunta: ¿cuánto es ")
.AppendFormat("{0} por {1}?", n, m);
string s = text.ToString();
Este código puede resultar extraño, así que expliquémoslo punto por punto. Primero, vemos que existe un método Append, el cuál añade al búfer una cadena de texto. De hecho, el método se encuentra sobrecargado para incorporar como parámetros todos los tipos base de .NET: bytes, ints, floats, decimales, DateTimes, etc.
Otro método es AppendFormat. Éste funciona igual que Append, con la diferencia que reemplaza en el texto las llaves {0}, {1}, {2}, etc., por el parámetro correspondiente en la posición 0, 1, 2, etc. De hecho, si pudieras ver el código de String.Format, verías algo así:
public static string Format(string text, params object[] objs)
{
StringBuilder b = new StringBuilder();
b.AppendFormat(text, objs);
return b.ToString();
}
Ahora bien, tanto Append como AppendFormat regresan una instancia a StringBuilder. De hecho, la instancia que regresan es la propia instancia. Es decir, hacen un return this. Si pudieras ver el código de Append, verías algo así:
public StringBuilder Append(string text)
{
// hacer algo con text
return this;
}
¿Por qué hacer esto? Ah, pues para que precisamente puedes encadenar las llamadas a Append y AppendFormat de la forma en que hicimos en el ejemplo. Este es un patrón de diseño que comúnmente se aplica en las clases que implementan el patrón Builder.
¿Se puede escoger las opciones de formato de un texto?
¡En efecto! Una de las sobrecargas de AppendFormat incluye un IFormatProvider como parámetro, así que para formatear el texto con una cultura especial puedes usar dicha sobrecarga.
float f = 1983.42;
CultureInfo esmx = new CultureInfo("es-MX");
CultureInfo eses = new CultureInfo("es-ES");
StringBuilder b = new StringBuilder()
.AppendFormat(eses, "Número español: {0}\n", f)
.AppendFormat(esmx, "Número mejicano: {1}\n", f);
Console.WriteLine(b);
/* Imprime:
Número español: 1.983,42
Número mejicano: 1,983.42
*/
Aparte de un CultureInfo, puedes pasar un NumberFormatInfo para el formateo de números, un DateTimeFormatInfo para el formateo de fechas, o bien puedes implementar tu propio IFormatProvider / ICustomFormatter.
¿Qué operaciones podemos hacer sobre el texto con el StringBuilder?
Evidentemente Append y AppendFormat, junto con ToString, son los métodos más utilizados. Sin embargo, también puedes realizar las siguientes operaciones.
1.- Eliminar todo el contenido del búfer, mediante el método Clear.
2.- Añadir un texto seguido de una nueva línea, mediante AppendLine.
3.- Copiar un bloque de caracteres por posición, a un array de caracteres, mediante CopyTo.
4.- Insertar caracteres en una posición determinada. El método Insert, funciona similar a Append, sólo que se hace en una posición del búfer determinada.
5.- Eliminar un rango de caracteres del búfer, mediante Remove.
6.- Asegurar la capacidad de un búfer, mediante EnsureCapacity.
7.- Remplazar una sub-cadena de texto por otra, mediante Replace.
StringBuilder text =
new StringBuilder("Tres tristes tigres tragaban trigo en un trigal");
text.EnsureCapacity(200);
// text.Capacity >= 200
text.AppendLine();
// añade un carácter \n al final
char[] chars = new char[10];
text.CopyTo(13, chars, 0, 6);
// chars == { t, i, g, r, e, s }
text.Insert(12, 42);
// text == "Tres tristes42 tigres tragaban trigo en un trigal"
text.Remove(5, 10);
// text == "Tres tigres tragaban trigo en un trigal"
text.Replace("tigres", "pollos");
// text == "Tres pollos tragaban trigo en un trigal";
text.Clear();
// text == ""
// text.Capacity >= 200, ésta propiedad no se afecta
¿Qué otros métodos para manipular texto existen?
Básicamente hay dos categorías: la manipulación de texto directa y la búsqueda de cadenas avanzada. Esta última utiliza expresiones regulares, lo cual queda fuera del alcance de esta entrada.
Para la manipulación de texto directa, la clase String expone diferentes métodos que nos ayudan con esto. Básicamente puedes realizar lo siguiente.
1.- Comparar cadenas de texto contra otras cadenas, otros valores o sub-cadenas.
2.- Concatenar cadenas, valores o sub-cadenas.
3.- Buscar valores, sub-cadenas de texto, etc.
4.- Formateo de cadenas de texto.
5.- Normalizar cadenas de texto (i.e. cambiar caracteres Unicode combinados por un solo carácter).
6.- Unir y separar cadenas de texto a partir de arrays, cadenas u objetos.
7.- Remover y remplazar caracteres y valores.
8.- Transformar los valores internos de la cadena de texto.
9.- Convertir cadena de texto a otros tipos de datos.
¿Cómo se pueden comparar cadenas de texto entre sí?
Hay diferentes tipos de comparaciones. La primera es la de igualdad, y el método en cuestión es Equals. Este método viene en muchos sabores. En primer lugar, permite comparar contra cualquier objeto, dado que sobrescribe Object.Equals. Sin embargo, esta comparación regresará false si el parámetro no es un string.
El segundo sabor es el Equals con una cadena de texto como parámetro. Este método hace una comparación carácter a carácter, se acuerdo a la cultura actual. String tiene un método estático homónimo que compara dos cadenas. Ambos métodos hacen lo mismo.
string s1 = "Pollo"; string s2 = "Pollo"; string s3 = "pollo"; bool val; val = s1.Equals(s2); // val == true val = s2.Equals(s3); // val == false val = string.Equals(s1, s3); // val == false val = string.Equals(s2, s1); // val == true
El tercer sabor es similar al anterior: dos métodos Equals, uno de instancia y otro estático, que adicional a la cadena de texto, toma como parámetro una enumeración que indica el tipo de comparación a realizar: cultura actual o invariante, ignorar capitalización (mayúsculas y minúsculas) para la cultura actual o cultura invariante, o bien comparar de forma ordinal tomando en cuenta e ignorando la capitalización.
string s1 = "Pollo"; string s2 = "Pollo"; string s3 = "pollo"; bool val; // val == true val = s2.Equals(s3, StringComparison.CurrentCultureIgnoreCase); // val == true val = string.Equals(s1, s3, StringComparison.InvariantCultureIgnoreCase);
¿Y cómo comparo cadenas alfabéticamente?
Con el siguiente tipo de comparación de relación: mayor qué y menor qué. Cuando se comparan dos caracteres, se dice que uno es mayor que el otro, si el primero está después en la tabla de posiciones Unicode. Una forma fácil de ver esto es en el programa Mapa de Caracteres, de Windows.

Aquí vemos que N es menor que Q, y que Q es menor que n minúscula. Por otra parte, también podemos comparar cualquier tipo de símbolos, según dicha tabla.
Así pues, decimos que una cadena de texto es menor que otra cuando conforme se van comparando carácter a carácter, se encuentra conque un carácter es menor que el de la otra en el mismo índice.
azul < carro, porque a < c.
auto < azul porque a == a, y u < z.
ampolla < amputar porque a == a, m == m, p == p, o < u.
Y así sucesivamente. Aquí vale la pena aclarar que las comparaciones pueden hacerse de dos formas: invariantes o por cultura. Una comparación por cultura toma en cuenta el idioma, y ciertas reglas explícitas de comparación pueden ser verdaderas para una cultura, pero falsas para otra. Por ejemplo:
ß == ss para de-DE (alemán de Alemania) y falso en español.
eßen == essen // de-DE
eßen > essen // es-ES
á == a para español, pero á > a para alemán.
ámpula == ampula // es-ES
ámpula > ampula // en-US
La comparación invariante no distingue entre culturas.
El primer método de comparación que veremos, según las reglas que hemos visto, es Compare. Éste es un método estático que nos permite comparar entre cadenas de texto. Prácticamente todos los métodos de comparación que veremos regresan un valor entero (Int32): menor a cero cuando la primera cadena es menor que la segunda, mayor a cero cuando la primera cadena es mayor a la segunda, o cero si son iguales (en cuyo caso, Equals regresaría true).
El método Compare tiene muchas sobrecargas, que permiten indicar cultura, si se ignora capitalización o no, si se comparan sub-cadenas, si se compara con opciones (ignorar capitalización, símbolos, espacios en blanco, etc.) y así sucesivamente. Algunos ejemplos a continuación (suponiendo que mi cultura actual es español de México).
int ret;
CultureInfo dede = new CultureInfo("de-DE");
ret = string.Compare("Das Maedchen", "Das Mädchen");
// ret < 0 porque a < ä
ret = string.Compare("Das Maedchen", "Das Mädchen", true, dede);
// ret == 0 porque ae == ä en alemán
ret = string.Compare("das maedchen", "DAS MÄDCHEN",
false, dede);
// ret == 0 porque se ignora capitalización y ae == Ä en alemán
string url = "https://fermasmas.wordpress.com";
ret = string.Compare(url, 0, "http:", 0, 5,
StringComparison.InvariantCultureIgnoreCase);
// ret == 0 porque se compara url con http: en los primeros cinco caracteres.
Etcétera. El método Compare es estático, pero la clase String tiene un método a nivel de instancia, llamada CompareTo. Este método funciona prácticamente igual que Compare, aunque sólo tiene dos sobrecargas: una que compara contra un objeto, el cual se evalúa a string (i.e. ToString()); y otra que compara contra otro string, tomando en cuenta capitalización y cultura actual.
int ret;
string str = "Das Maedchen";
ret = str.CompareTo("Das Mädchen"); // ret < 0 porque a < ä
ret = str.CompareTo("Das maedchen"); // ret > 0 porque M > m
str = "42";
ret = str.CompareTo(42); // ret == 0 porque "42" == (42).ToString()
Otro asunto: existe un método estático llamado CompareOrdinal. Este método hace la comparación evaluando los valores numéricos de cada carácter. Así, es totalmente agnóstico de la cultura empleada.
Ya por último, si en algún momento quieres comparar una cadena de texto vacía o nula, en lugar de hacer esto:
if (str != null || str != "") { … }
Mejor hacer esto:
if (!string.IsNullOrEmpty(str)) { … }
El método IsNullOrEmpty regresa verdadero si el parámetro es nulo o está vacío. También existe isNullOrWhiteSpace, si el parámetro es nulo, está vacío o sólo contiene espacios blancos.
¿Qué hay respecto a la concatenación de cadenas?
La forma más fácil es usar los operadores + y +=. Pero ya vimos que no es muy eficiente, sobre todo cuando concatenamos muchas cadenas y valores. Asimismo, ya hablamos sobre String.Format y StringBuilder. Podemos usar ambas para concatenar cadenas.
Adicional a esto, la clase String cuenta con un método estático, llamado Concat. Este método, con todas sus sobrecargas, permite concatenar dos o más cadenas, objetos y valores. Al final, regresa una cadena de texto con la cadena final.
object[] vals = { "Dos y dos son ",
2 + 2,
", cuatro y dos son ",
4 + 2 };
string s = string.Concat(vals); // "Dos y dos son 4, cuatro y dos son 6"
¿Y cómo podemos realizar búsquedas de cadenas de texto?
Hay muchos métodos encaminados a buscar cadenas de texto de forma directa (es decir, sin utilizar expresiones regulares). Se me ocurre clasificarlos en tres grupos: aquellos que indican concordancia, aquellos que regresan un índice, y aquellos que regresan una porción de texto.
Para el primer grupo, tenemos los siguientes métodos que presentamos a continuación. Todos regresan true o false, dependiendo de si se cumple la condición de búsqueda. Nota: consideremos la siguiente cadena para los ejemplos.
string s = "Cuántos pollos comen melón, cuántos sandía";
1.- El método Contains regresa true si una cadena de texto está contenida dentro de otra.
s.Contains(""); // true, una cadena vacía siempre está contenida.
s.Contains("pollo"); // true;
s.Contains("chabacano"); // false
2.- El método EndsWith regresa true si una cadena de texto tiene una terminación determinada. Toma en cuenta cultura y comparación de cadenas (i.e. ordinal, invariante o sensible a la cultura actual).
s.EndsWith("sandía"); // true
s.EndsWith("sandia"); // false
s.EndsWith("SANDÍA", StringComparison.CurrentCultureIgnoreCase); // true
s.EndsWith("SANDIA", true, new CultureInfo("es-MX")); // true
3.- La contraparte al método anterior es StartsWith, que regresa true si una cadena de texto tiene un comienzo determinado.
s.StartsWith("Cuántos"); // true
s.StartsWith("Cuantos"); // false
s.StartsWith("CUÁNTOS", StringComparison.CurrentCultureIgnoreCase); // true
s.StartsWith("CUANTOS", true, new CultureInfo("es-MX")); // true
El segundo grupo cuenta también con varios métodos, que básicamente regresan un número. Éste es el índice a partir del cual se encuentra la cadena a ser buscada. Si el valor es menor a cero, es que la cadena no fue encontrada.
1.- El método directo para encontrar el índice es IndexOf. Este método busca la primera coincidencia de la cadena de texto pasada como parámetro. IndexOf busca también carateres, y permite especificar opciones de formato, como cultura o capitalización.
int index;
index = s.IndexOf("pollo"); // index == 8
index = s.IndexOf("Cuántos"); // index == 0
index = s.IndexOf("cuántos"); // index == 28
index = s.IndexOf("cuántos"
StringComparison.CurrentCultureIgnoreCase); // index == 0
index = s.IndexOf("Melón"); // index == -1
index = s.IndexOf("Melón",
StringComparison.CurrentCultureIgnoreCase); // index == 21
2.- Un converso de IndexOf es LastIndexOf. Hace lo mismo, sólo que busca la última coincidencia, a diferencia de IndexOf que busca la primera coincidencia.
int index;
index = s.LastIndexOf("Cuántos"); // index == 0
index = s.LastIndexOf("cuántos"); // index == 28
index = s.LastIndexOf("cuántos",
StringComparison.CurrentCultureIgnoreCase); // index == 28
3.- Existe un método que permite buscar un conjunto de caracteres, en un array, y regresa el índice del primer carácter encontrado. Éste es IndexOfAny.
int index;
char[] chars = new char[] { 'n', 'o', 's' };
index = s.IndexOfAny(chars); // index == 3, en "Cuántos"
4.- El converso es LastIndexOfAny, que busca caracteres pero comenzando por el último.
int index;
char[] chars = new char[] { 'o', 'n', 's' };
index = s.IndexOfAny(chars); // index == 38, en "sandía"
El último grupo es un solo método, y es similar a la familia IndexOf, pero al revés: le pasas un índice y te regresa una sub-cadena. Este método es Substring, el cual tiene dos sobrecargas: la primera obtiene la cadena a partir de un índice, y la segunda obtiene la cadena a partir del índice y de una longitud determinada.
string str = s.Substring(8, 6); // str == "pollos"
// Este método funciona particularmente bien en conjunto con IndexOf.
string s = "Cuántos {pollos} comen melón, cuántos sandía";
string io = s.IndexOf('{');
string if = s.IndexOf('}');
string ss = s.Substring(io, if - io);
Console.WriteLine(ss); // pollos
Ok, basta de búsquedas. ¿Cómo se puede formatear cadenas de texto?
Ya hemos analizado tanto string.Format como StringBuilder.AppendFormat, métodos que nos ayudan a generar formato. Pero podemos ahondar un poquito más. El método string.Format le pasa el control directamente a StringBuilder, por lo que hablaremos de ambos métodos de forma indistinta, bajo este entendido.
En fin, String.Format siempre interactúa con respecto a la cultura local. Normalmente esto suele ser suficiente: si la computadora está en español de México, pues tendrás puntos decimales, comillas de miles, etc. Si estás en español de España, pues es al revés. Hay ocasiones, sin embargo, en las que necesitamos forzar el uso de un idioma o cultura en particular. Para ello, String.Format (y de hecho prácticamente cualquier método que implique conversión entre un tipo de dato y texto) tiene una sobrecarga que permite pasar por parámetro un IFormatProvider.
El IFormatProvider por excelencia es CultureInfo. Esta clase representa una cultura, y por lo tanto el objeto de formato que implementa formatea las cadenas de texto conforme a las reglas de esa cultura.
CultureInfo japones = new CultureInfo("ja-JP");
CultureInfo aleman = new CultureInfo("de-DE");
CultureInfo espanol = new CultureInfo("es-MX");
float c = "42.06";
string s = string.Format("{0:C}", japones);
Console.WriteLine(s);
string s = string.Format("{0:C}", aleman);
Console.WriteLine(s);
string s = string.Format("{0:C}", espanol);
Console.WriteLine(s);
/*
* ¥ 42.06
* 42,06 €
* $ 42.06
*/
Veamos un par de cosas que pasaron. En primer lugar creamos tres objetos de cultura: japonés de Japón, alemán de Alemania, y español de México. Luego, usamos string.Format para realizar un formato. Vemos que en la cadena de formato, pasamos {0:C}. Normalmente pasamos {0}. Ese :C de más quiere decir que formatearemos la entrada como una moneda, en este caso el yen japonés, el euro alemán y el peso mexicano. La C determina el tipo de formato, y la cultura, la forma de llevarlo a cabo.
Otros ejemplos son: D para decimal, E para notación exponencial o científica, F para punto decimal fijo (i.e. 4 => 4.0), G para la versión general, es decir, la más compacta posible; N para un número con separador de miles, decimales, etc.; P para porcentaje, R para redondear, X para hexadecimal.
s = string.Format("{0:D}", 99901); // s == 99901
s = string.Format("{0:D10}", 99901); // s == 0000099901
s = string.Format("{0:E}", 1983.42"); // s == 1.98342E+003
s = string.Format("{0:F2}", 1983"); // s == 1983.00
s = string.Format("{0:F3}", 1983.4266"); // s == 1983.427
s = string.Format(japones, "{0:N}", 1983.55); // s == 1.983,55
s = string.Format("{0:P}", 0.42); // s == 42 %
s = string.Format("{0:X4}", 255); // s == 00FF
Si ninguna de estas nos satisface, podemos crear nuestro propio formato mediante el formato de números especializado. Para hacer esto, podemos colocar en lugar del D, E, C, etc., un 0 para representar un dígito, si existe, o un cero si no; un # para representar un dígito si existe, si no, no muestra nada; El punto . para separar decimales y la coma para separar grupos. Asimismo, tenemos % para porcentaje, ‰ para por-miles, E0 para notación exponencial, ‘cadena’ para poner una cadena de texto fija.
s = string.Format("{0:0,00.00#:D}", 99.1); // s == 0,99.10
s = string.Format(aleman, "{0:0,00.00#:D}", 99.1); // s == 0.99,10
s = string.Format("{0:000,000.000}", 9991); // s == 009,991.000
s = string.Format("{0:#,#00}", 99.1); // s == 99
s = string.Format("{0:#,#00}", 9.1); // s == 09
s = string.Format("{0:#,#00}", 9999.1); // s == 9,999
s = string.Format("{0:##-###-##}", 99942); // s == 999-42
s = string.Format("{0:##-###-##}", 4299942); // s == 42-999-42
El formato también podemos aplicarlo a las fechas, de forma muy similar a como se aplica para números. Existen muchos formatos, pero los más utilizados son los siguientes: se usa la d y D para una fecha corta y una fecha larga, respectivamente; f y F para fecha con tiempo corto y largo, u y U para formato universal corto y largo.
CultureInfo enUS = new CultureInfo("en-US");
CultureInfo deDE = new CultureInfo("de-DE");
CultureInfo esMX = new CultureInfo("es-MX");
DateTime tm = new DateTime(2012, 12, 04, 11, 05, 42);
s = string.Format(esMX, "{0:d}", tm); // s == 12/04/2012
s = string.Format(esMX, "{0:d}", tm); // s == 04/12/2012
s = string.Format(deDE, "{0:D}", tm); // s == Dienstag, 4. Dezember 2012
s = string.Format(enUS, "{0:f}", tm); // s == Tuesday, 4 Dic, 2012 11:05
Etcétera. También podemos utilizar formato especial usando y, M, d, m, h, M, s para representar año, mes, día, minuto hora, segundo, etc. Por ejemplo, cuatro yes suponen año en formato de cuatro dígitos, como 1983. Dos yes y tendríamos 83.
s = string.Format(esMX, "{0:ddd d MMM}", tm);
// s == mar 4 dic
s = string.Format(esMX, "{0:dddd d MMMM}", tm);
// s == martes 4 diciembre
s = string.Format(esMX, "{0:H mm ss}", tm);
// s == 11 05 42
s = string.Format(esMX, "{0:y yy yyyy yyyyy}", tm);
// s == 2 12 2012 02012
¿Y qué significa eso de ‘normalizar’?
Cuando hablamos de normalización, en general, queremos decir que estandarizamos algo, es decir, que lo dejamos en su forma más sencilla. Haciendo una comparación un poco simple, pero ilustrativa, consideremos el siguiente número.
![]()
A primera instancia luce complicado. Sin embargo, si resuelves, te darás cuenta que el número es 42. Pues bien, decimos que 42 es la forma normalizada del número anterior.
Ahora bien, cuando hablamos de texto, la normalización también significa simplificar la cadena conservando el mismo valor. En este caso, la simplificación se da a nivel binario.
Para entender lo anterior, necesitamos recordar que las cadenas de texto son una secuencia de caracteres Unicode. Cada carácter Unicode está formado por dos bytes. Ahora bien, a nivel textual, existen algunos caracteres que pueden representarse por dos o más pares de bytes totalmente diferentes. Es decir, a nivel binario los valores son diferentes, pero a nivel de texto son iguales.
Por ejemplo, el carácter ắ podemos representarlo de tres formas:
s1 = 0x1EAF
s2 = 0x0103 + 0x0301
s3 = 0x0061 + 0x0306 + 0x0301
Cada uno de los números significa representa un byte. Así, podemos crear las siguientes cadenas de texto.
string a1 = new string( new char[] { '\u1EAF' });
string a2 = new string( new char[] { '\u0103', '\u0301' });
string a3 = new string( new char[] { '\u0061', '\u0306', '\u0301' });
Las tres cadenas imprimirían el mismo carácter. Pero al compararlas entre sí, especialmente usando la forma de comparación con String.CompareOrdinal, ninguna de las tres será igual a las demás. Estas divergencias pueden complicar ciertos algoritmos, como búsquedas de cadenas de texto.
Como quizás ya hayas adivinado, la normalización de una cadena de texto consiste, precisamente, en simplificar la representación binaria de un carácter o secuencia de caracteres. En el ejemplo anterior, significaría convertir a2 y a3 en a1. Esto es posible debido a que el estándar de Unicode define algunos algoritmos para hacer esto, llamados imaginativamente C, D, KC, y KD. Cada uno define ciertas reglas a seguir. El más utilizado, y el estándar en .NET, es el C.
La clase String, así, define un método llamado Normalize con dos sobrecargas, una que utiliza el algoritmo C por default, y una que permite seleccionar el tipo de algoritmo. Asimismo, define un método IsNormalized, que nos permite saber si una cadena está normalizada o no.
string a1 = new string( new char[] { '\u1EAF' });
string a2 = new string( new char[] { '\u0103', '\u0301' });
string a3 = new string( new char[] { '\u0061', '\u0306', '\u0301' });
if (!a1.IsNormalized())
a1 = a1.Normalize();
if (!a2.IsNormalized(NormalizationForm.FormKD));
a2 = a2.Noramlize(NormalizationForm.FormKD);
if (!a3.IsNormalized());
a3 = a3.Noramlize();
Cuando trabajamos con archivos o bases de datos y tenemos campos sobre los que haremos búsquedas (por ejemplo, cláusula "where" en una consulta "select" de SQL), es muy recomendable que normalices el texto antes de guardarlo en el archivo o base de datos.
¿Cómo puedo unir y separar cadenas de texto?
Ésta es útil y facilita. Para unir cadenas de texto, necesitamos ponerlas todas en un array o cualquier colección que implemente IEnumerable. Luego, invocamos al método estático Join. Este método toma como primer parámetro el separador. Es decir, cuando las unas puedes querer separarlas por algún carácter o cadena. Esta es tu oportunidad. El segundo parámetro es la colección.
string[] cylons {
"John",
"Leoben",
"D'Anna",
"Simon",
"Caprica Six",
};
string text1 = string.Join("\nCylon: ", cylons);
Console.WriteLine(text1);
/* imprime:
Cylon: John
Cylon: Leoben
Cylon: D'Anna
Cylon: Simon
Cylon: Caprica Six
*/
string text2 = string.Join(", ", cylons);
Console.WriteLine(text2);
/* imprime:
John, Leoben, D'Anna, Simon, Caprica Six
*/
Para separar la cadena, hay que usar el método Split. Este método no estático toma como parámetro una cadena que representa un separador. Cada que se encuentre un separador, se corta la cadena y el bloque se añade a un array. Si el separador nunca es encontrado, entonces el array tendrá una sola cadena: la cadena original.
string text = "John-Leoben-D'Anna-Simon-Caprica Six";
string[] cylons = text.Split('-');
foreach (string cylon in cylons) {
Console.WriteLine(cylon);
}
/* imprime:
John
Leoben
D'Anna
Simon
Caprica Six
*/
Ok, ¿y ahora cómo remuevo o reemplazo caracteres?
Tenemos un par de métodos para ello. En primer lugar, Remove se encarga de remover los caracteres a partir de un índice y una longitud determinada.
string text = "John-Leoben-D'Anna-Simon-Caprica Six"; text = text.Remove(5, 7); // text == "John-D'Anna-Simon-Caprica Six" text = text.Remove(0, 5); // text == "D'Anna-Simon-Caprica Six" text = text.Remove(6); // del 6to carácter en adelante // text == "D'Anna"
Y así es que nos quedamos con Lucy Lawless.
También podemos usar Replace. Este método substituye un carácter por otro, o una cadena de texto por otra.
string text = "John-Leoben-D'Anna-Simon-Caprica Six";
text = text.Replace("John", "Saul")
.Replace("Leoben", "Galen")
.Replace("Simon", "Ellen")
.Replace("D'Anna", "Anders");
// text == "Saul-Galen-Anders-Ellen-Caprica Six"
text = text.Replace('a', '*')
.Replace('l', '1');
// text == "S*u1-G*1en-Anders-E11en-C*prica Six"
Dado que cada Replace regresa una cadena regresa de texto, es posible encadenarlas de esta forma. Por cierto, que Replace puede actuar también como Remove, si somos imaginativos:
string text = "John-Leoben-D'Anna-Simon-Caprica Six";
text.Replace("John-", string.Empty)
.Replace("D'Anna-", string.Empty)
.Replace("-Caprica Six", string.Empty);
// text == "Leoben-Simon
¿Y de qué forma podemos transformar valores de una cadena?
Existen varias transformaciones que podemos hacer. La primera es que podemos insertar caracteres dentro de una cadena, mediante el método Insert. A este método le pasamos un índice y la cadena a insertar.
En segundo lugar, podemos alinear texto al margen izquierdo o margen derecho mediante las funciones PadLeft y PadRight, respectivamente. El primer parámetro es el número de caracteres totales a alinear. El segundo, el carácter con el que queremos llenar la alineación.
Convertir entre mayúsculas y minúsculas también entran en acción. Tenemos a ToLower y ToUpper, por supuesto, para convertir la cadena a puras minúsculas o puras mayúsculas. Una sobrecarga de estos métodos toma como parámetro un objeto CultureInfo, que nos permite especificar el idioma. Si no pasamos cultura, entonces se toma la cultura por default. Si queremos convertir sin importar la cultura, usamos ToLowerInvariant y ToUpperInvariant.
Y ya por último, a veces querremos eliminar espacios en blanco. Esto es muy útil sobre todo cuando trabajamos con bases de datos, que nos llega con espacios en blanco antes y después. Entonces podemos usar el método TrimStart y TrimEnd, para eliminar los espacios al inicio y al final de la cadena, respectivamente. O Trim, que lo hace en las dos al mismo tiempo. Por cierto, si a algún método le pasamos un array de caracteres, dichos métodos los eliminarán antes o después. Básicamente estos tres métodos son el converso de PadLeft y PadRight.
string str = "Todos los pollos van al cielo.";
str = str.Insert(17, "siempre ");
// str == "Todos los pollos siempre van al cielo."
str = str.PadLeft(45);
// str == " Todos los pollos siempre van al cielo."
str = str.PadRight(50);
// str == " Todos los pollos siempre van al cielo. "
str = str.PadRight(55, '*');
// str == " Todos los pollos siempre van al cielo. *****"
str = str.ToUpper();
// str == " TODOS LOS POLLOS SIEMPRE VAN AL CIELO. *****"
str = str.ToLower();
// str == " todos los pollos siempre van al cielo. *****"
str = str.TrimLeft();
// str == "todos los pollos siempre van al cielo. *****"
str = str.TrimRight('*');
// str == "todos los pollos siempre van al cielo. "
str = str.Trim();
// str == "todos los pollos siempre van al cielo."
Y ya para concluir la lista (¡uf!), ¿cómo se convierten cadenas de texto en otros tipos de dato?
La verdad es que String implementa explícitamente la interfaz IConvertible. Esta interfaz permite convertir a otros tipos de datos. Por lo que a partir de una cadena, sólo tienes que obtener la referencia directa a IConvertible y usar el método que apetezcas. Nota que para todos los tipos de datos numéricos aplican cuestiones de formato.
CultureInfo ci = new CultureInfo("es-ES");
string str "42,06";
IConvertible cv = str as IConvertible;
double d = cv.ToDouble(ci);
str = "True";
cv = str as IConvertible;
bool b = cb.ToBoolean();
str = "04/12/2012";
ci = new CultureInfo("es-MX");
cv = str as IConvertible;
DateTime tm = cv.ToDateTime(ci);
Esto es quizás un poquito engorroso. Una alternativa quizás un poco más sencilla es utilizar los métodos de conversión (usualmente estáticos) que proveen las clases de los tipos básicos. Por ejemplo, casi todas estas clases tienen dos métodos sobrecargados: Parse y TryParse. Ambas intentan convertir una cadena de texto en su tipo base (por ejemplo, Int32.Parse convierte a int, Double.Parse convierte a double, etc.). La diferencia es que Parse lanza una excepción si no puede realizarse la conversión, y TryParse regresa un valor por default si no puede realizarla.
CultureInfo ci = new CultureInfo("es-ES");
string str = "42,06";
double d = double.Parse(str, ci);
int i;
bool ret = int.TryParse("NoEsNúmero", out i);
// ret == false y i == 0
str = "True";
bool b = bool.Parse(str
str = "04/12/2012";
ci = new CultureInfo("es-MX");
DateTime tm;
ret = DateTime.TryParse(str, ci);
// ret == true y tm == 4/12/2012
Por último, la plataforma también contiene la clase Convert. Esta clase estática tiene muchos métodos para convertir de cualquier tipo de dato a cualquier otro tipo de dato.
CultureInfo ci = new CultureInfo("es-ES");
string str = "42,06";
double d = Convert.ToDouble(str, ci); // d == 42.06
int i = Convert.ToInt32("1.983", ci); // i == 1983
i = Convert.ToInt32("0xFF", 16); // i == 255
i = Convert.ToInt32("100110000011111001", 2) // i == 155897
str = "True";
bool b = Convert.ToBoolean(str); // b == true;
str = "04/12/2012";
ci = new CultureInfo("es-MX");
DateTime tm = Convert.ToDateTime(str, ci); // tm == 4/12/2012
¿Qué nos falta?
Bueno, hasta ahora hemos visto cómo manipular cadenas de texto, y hemos visto mejores prácticas, en particular, utilizando a StringBuilder. Nos falta un tema que es importante, aunque sale un poquito del alcance de esta entrada: los flujos de datos.
¿Qué tienen que ver los flujos de datos?
Primero, un flujo de dato es una secuencia ordenada de bytes. En .NET, la clase que representa a los flujos se llama Stream, ubicada en el espacio de nombres System.IO. De momento no ahondaremos más en el tema de los flujos (puedes consultar la entrada Todo sobre flujo de datos). Pero retomaremos el concepto de leer y escribir datos en los flujos.
¿Qué la clase Stream no tiene métodos para leer y escribir?
Sí, pero de hecho esta clase no escribe sobre un Stream, sino que…
¿Y entonces?
Calma. Estas clases heredan de un par: TextReader y TextWriter. Estas clases base son las usadas para leer y escribir en flujos, y las clases derivadas: StreamReader y StreamWriter nos permiten hacerlo en un flujo. Sin embargo, hay veces en la que nos interesará reutilizar los algoritmos escritos para TextReader y TextWriter, pero para crear cadenas de texto. Ese es el propósito de estas dos clases: StringReader y StringWriter.
Ambas clases guardan todo el flujo dentro de un… ajam… StringBuilder. Así, podemos usarlas de esta forma.
StringWriter w = new StringWriter();
w.WriteLine("Todos los pollos van al cielo.");
w.Write("Un número: ");
w.WriteLine(42);
w.Write("Un booleano: ");
w.WriteLine(false);
str = w.ToString(); // construye la cadena de texto
w.Close();
StringReader r = new StringReader(str);
do
{
str = r.ReadLine();
Console.WriteLine("Ln: {0}", str ?? "EOF");
}
while (str != null);
r.Close();
/* imprime:
Ln: Todos los pollos van al cielo.
Ln: Un número: 42
Ln: Un booleano: false
*/
Realmente usarlas así no aporta mucho, pues podemos usar StringBuilder directamente. Sin embargo, puede servirnos para reutilizar algoritmos de lectura / escritura de datos, sin importar la fuente. Y ahí StringBuilder no nos puede ayudar, me temo.
void CreateHtml(TextWriter w)
{
w.WriteLine("<html>");
w.WriteLine("<body>");
w.WriteLine("<h1>Todos los pollos van al cielo.</h1>");
w.WriteLine("<p>Lorem ipsum dolor sit amet, qua micas la pater "
+ "santis sempire damore denarii.</p>");
w.WriteLine("</body>");
w.WriteLine("</html>");
}
StreamWriter file = new StreamWriter("C:\\miarchivo.txt");
CreateHtml(file);
file.Close();
StringWriter text = new StringWriter();
CreateHtml(text);
Console.WriteLine(text.ToString());
text.Close();
Aquí vemos cómo podemos escribir el texto a un archivo o a la consola, reutilizando el mismo método CreateHtml.
¿Y ahora sí ya estuvo?
Ya estuvo. Las cadenas de texto son el alma de todos los programas, pues es como mejor representamos la información. Cuídalas para que no sufras por memoria. Siempre prefiere usar StringReader y StringWriter sobre string, y StringBuilder sobre todas. También revisa las expresiones regulares, otra forma de buscar cadenas de texto, más avanzada.
Nos vemos pronto con más de esta serie: C# 101.
Gestión de memoria y recursos en .NET
Una de las características más importantes de C# y .NET es que tanto lenguaje como plataforma gestionan la memoria en automático. Para quienes venimos de C++, estábamos muy acostumbrados a gestionar nuestros propios recursos.
class address {
public:
std::wstring street;
int number;
std::wstring city;
std::wstring postal_code;
address() { … }
address(const address& copy) { … }
~address() { }
bool full_address () const { … }
bool validate() const;
};
class employee {
public:
std::wstring name;
int id;
double income;
address* main_address;
address* office_address;
employee() { … }
~employee() {
if (main_address != nullptr)
delete main_address; // liberar memoria
if (office_address != nullptr)
delete office_address; // liberar memoria
}
…
};
employee* e = new employe();
e->name = L"Fernando Gómez";
e->income = 500.00;
e->id = 42;
e->main_address = new address();
e->main_address->street = "Odessa";
e->main_address->number = 42;
e->main_address->postal_code = "38102";
e->office_address = nullptr;
// hacer algo con e
delete e; // liberar memoria
Este es un ejemplo sencillo. La clase address tiene un destructor que no hace nada, pero la clase employee tiene un destructor que sí hace algo: libera la memoria de los punteros existentes main_address y office_address. En C++ estábamos acostumbrados a liberar la memoria de forma manual, invocando la sentencia delete, como se ha visto. También estábamos acostumbrados, por supuesto, a que a alguien se le olvidada liberar la memoria y por tanto teníamos fugas de memoria.
En .NET, por supuesto, todo esto cambió. La máquina virtual de .NET incorpora un componente, llamado el colector de basura (garbage collector, GC), cuyo propósito es liberar la memoria, previo análisis de recursos. En palabras sencillas, el programador ya no tiene que preocuparse por liberar los recursos de memoria, y por tanto ya nunca tendremos fugas de memoria.
Lo cuál, por supuesto, es algo falso.
Fugas de memoria en .NET
En .NET uno piensa que no hay fugas de memoria. En principio esto es cierto. Pero en general lo es sólo para las clases y componentes más sencillos. En efecto, cualquier componente complejo que use recursos de sistema, puede presentar fugas de memoria.
Para entender las fugas, debemos hacer algunas definiciones. Primero, diremos que cuando una liberación de recursos se ejecuta al instante, en cuanto se invoca, entonces ésta es una liberación determinista de recursos. Por ejemplo, la sentencia delete de C++ que vimos arriba es una liberación determinista: en cuanto llegamos a la sentencia, en ese momento se invocan destructores en orden, uno a uno, y se liberan los recursos. Una liberación no determinista es, por supuesto, cuando un recurso no se libera al instante. Es decir, se da la orden de liberar, pero no se hace al momento, e incluso puede tardar tiempo en ejecutarse. Se infiere que una liberación no determinista es totalmente asíncrona, respecto del proceso que contiene el elemento a liberar.
Pues bien, en .NET tenemos el colector de basura. Este colector libera los recursos, y lo hace de forma no determinista. Las reglas bajo las cuales esto funciona son algo complejas, pero básicamente se fija si un objeto es alcanzable o no. Por ejemplo:
class A
{
}
class B
{
public A a;
}
B b = new B(); // se ubica B en memoria.
b.a = new A(); // se ubica A en memoria.
…
b.a = null; // ya no hay forma de recuperar a A.
Este sencillo ejemplo es ilustrativo. B contiene un objeto A. Creamos un objeto B, y luego creamos un objeto A y se lo asignamos a B.a. Después de unas operaciones cualesquiera, asignamos B.a a null. En este momento, ya no hay forma de recuperar una referencia a A. Aunque el objeto A siga vivo, ya no puede recuperarse. A partir de este momento, el colector de basura puede decidirse a liberar o reclamar los recursos. Pero puede decidir no hacerlo, e incluso puede pasar mucho tiempo antes de que suceda. Es más, puede ser que el objeto B sea reclamado antes que A. Pero el punto es que a partir de ahí, como dicen en EE. UU., all bets are off.
Entonces, según lo anterior, ¿cómo puede haber fugas de memoria? La respuesta pasa por entender que una fuga de memoria nunca es permanente. En los sistemas operativos actuales, modernos, la memoria es liberada automáticamente por éstos, cuando el hilo ejecutor termina. Así, las fugas de memoria de hoy en día hacen más referencia a la pérdida temporal de memoria. Es decir: tenemos un objeto que debería ser liberado de memoria, y como no lo hacemos, vamos consumiendo más y más memoria. En casos extremos, ¡hasta podemos acabárnosla!
Es en este sentido que .NET permite las fugas de memoria. Considera este ejemplo. Tenemos una clase que utiliza un recurso de sistema (por ejemplo, usamos el sistema de geo-localización que viene con Windows 7). Estos recursos de sistema, como son provistos por el sistema operativo, no son administrados. Esto quiere decir que son responsabilidad del programador liberarlos (por supuesto, un recurso administrado es un recurso que el colector de basura libera en automático de forma no determinista).
class GeoLocalizador
{
private IntPtr _manejadorSistema;
public GeoLocalizador() {
_manejadorSistema = InvocarApiDeSistema();
}
...
}
Esto nos presenta un dilema, por supuesto. Cuando instanciamos nuestra clase GeoLocalizador adquirimos recursos no administrados, representados por la variable miembro _manejadorSistema de tipo IntPtr (usada para los famosos HANDLEs del API de Win32). Sin embargo, dado que el colector de basura se encarga de liberar la memoria administrada, pero no los recursos no administrados, los recursos de _manejadorSistema nunca serán liberados (hasta que termine el proceso, como pasaría con cualquier programa de Windows). Esto, mis estimados, es una fuga de memoria.
Liberación no determinista de recursos
¿Qué hacemos entonces para liberar estos recursos? En C++ tenemos el concepto de destructor. Un destructor es un método especial de una clase que SIEMPRE es invocado cuando el objeto deja de existir (bien porque sale de alcance, bien porque se invoca una sentencia delete). Es la contraparte del constructor.
En C# tenemos un concepto similar: los finalizadores. En principio, el finalizador es el mismo concepto de un destructor, y quienes venimos de C++ solemos llamarlos con este segundo nombre, probablemente por nostalgia. Pero gente fuera de C++ y C# los conoce como finalizadores (muy particularmente, la gente que viene de Visual Basic .NET).
En .NET, la clase Object tiene un método protegido virtual, llamado Finalize. ¿Qué te crees? Pues que ese método es, justamente, ¡el finalizador! Y como todas las clases heredan de Object, pues entonces todas las clases tienen su método Finalize. Para liberar recursos cuando el objeto sea reclamado, bastará con sobrescribir al método Finalize y colocar ahí el código para liberar.
class GeoLocalizador
{
private IntPtr _manejadorSistema;
public GeoLocalizador() {
_manejadorSistema = InvocarApiDeSistema();
}
protected override void Finalize() {
InvocarLiberación(ref _manejadorSistema);
base.Finalize();
}
...
}
Fácil, ¿no? Si escribes un código similar… éste no compilará. ¡Auch! Y es que resulta que por conveniencia, C# define una sintaxis especial para los finalizadores, y por tanto no puede sobrescribirse Finalize. Esto por un par de razones. Primero, para emular la sintaxis de C++. Segundo, para evitar que algún programador olvide llamar a base.Finalize, o que declaren como sealed al método y no sealed a la clase. Así, como decía, tenemos que usar una sintaxis similar a la de C++:
class GeoLocalizador
{
private IntPtr _manejadorSistema;
public GeoLocalizador() {
_manejadorSistema = InvocarApiDeSistema();
}
~GeoLocalizador() {
InvocarLiberación(ref _manejadorSistema); // ok
}
...
}
Como ves, el finalizador utiliza el símbolo ~ seguido del nombre de la clase. No puede tener modificadores, como public, protected, virtual, etc. Y ya no es necesario invocar a la clase base: el compilador lo hace por nosotros.
Una nota importante, sobre todo si vienes de C++. En este lenguaje, se recomienda siempre incluir un destructor, aunque éste esté vacío, por buena práctica. Todo lo contrario en C#: incluye destructores (i.e. finalizadores) sólo cuando vayas a liberar recursos. Si no, abstente. Esto, porque el colector de basura es más eficiente cuando no tiene que ejecutar finalizadores, por lo que incluir uno vacío sólo ralentiza el proceso de liberación de memoria.
Cabe resaltar que incluir finalizadores, aunque nos garantiza que nuestros recursos no administrados se liberen, no nos garantiza cuándo. Es decir, en un escenario tradicional como en nuestra clase GeoLocalizador, incluir el finalizador nos garantiza que no exista una fuga de memoria: después que la instancia muera, el objeto será reclamado y por tanto el recurso no administrado será liberado. Pero no nos garantiza que nuestra memoria sea óptima.
Considera esta situación: tienes una forma de Windows Forms donde capturas los datos de contacto de una persona. Entre esos datos, quieres capturar sus coordenadas geográficas, por lo que incluyes un botón que al hacer clic, utilice la clase GeoLocalizador para obtener las coordenadas. Ese método podría lucir así:
private _geolocButton_Click(object sender, EventArgs args)
{
GeoLocalizador loc = new GeoLocalizador();
loc.CalcularPosicion();
_longText.Text = loc.Longitud.ToString();
_latText.Text = loc.Latitud.ToString();
}
En el método creamos instancias de GeoLocalizador. Una vez que el flujo del programa sale del método, GeoLocalizador queda referenciada y por tanto es susceptible de ser reclamada por el colector de basura, y por tanto, cuando eso ocurra, se liberarán los recursos no administrados. Pero como ya vimos que esto puede no ser instantáneo, imaginemos: ¿qué pasa si el GC decide no colectar objetos, y el usuario hace clic 10 veces en el botón? ¡Tendremos 10 instancias con memoria sin liberar! Más aún: ¿qué pasa si el sistema operativo sólo permite una instancia del geo localizador? Tendríamos que esperarnos a que el GC colectara para poder volver a utilizar la clase GeoLocalizador, y no hay forma de saber cuándo ocurrirá eso.
En situaciones similares, vemos que a veces es necesario contar con liberación de recursos de forma determinista.
Liberación determinista de recursos
Una liberación determinista debería ser muy sencilla. O más o menos. Es decir, al final, si queremos liberar un recurso, podemos simplemente crear un método LiberarRecursos y ya, ¿no?
class GeoLocalizador
{
private IntPtr _manejadorSistema;
public GeoLocalizador() {
_manejadorSistema = InvocarApiDeSistema();
}
~GeoLocalizador() {
InvocarLiberación(ref _manejadorSistema); // ok
}
public double Latitud { get; private set; }
public double Longitud { get; private set; }
public void CalcularPosicion() {
if (_manejadorSistema == null)
throw new InvalidOperationException("No hay manejador. ");
… // etc
}
public void LiberarRecursos() {
if (_manejadorSistema != null) {
InvocarLiberación(ref _manejadorSistema);
_manejadorSistema = null;
}
}
...
}
GeoLocalizador loc = new GeoLocalizador();
loc.CalcularPosicion();
_longText.Text = loc.Longitud.ToString();
_latText.Text = loc.Latitud.ToString();
loc.LiberarRecursos();
Pues sí, hemos alcanzado una liberación determinista de esta forma. Al final, invocamos LiberarRecursos y pues ya liberamos los recursos, ¿no? Hay que tener cuidado, sin embargo, porque en teoría una vez que invocamos LiberarRecursos hemos dejado el objeto en un estado inválido. Es decir, en teoría una vez liberado, ya no debería ser posible ser utilizado. Sin embargo, C# no nos impide hacer esto:
GeoLocalizador loc = new GeoLocalizador(); … loc.LiberarRecursos(); loc.CalcularPosicion(); // ¡oh-oh!
Después de LiberarRecursos, si invocamos a CalcularPosicion pues ya no tendría sentido y de hecho nuestro recurso no administrado ya está liberado y no podemos volver a utilizarlo. De hecho hemos puesto algunas salvaguardas para evitar que suceda: revisamos que si la variable interna en nula, lanzamos un InvalidOperationException. Sin embargo, nota que si se invoca a LiberarRecursos dos veces, no lanzará una excepción, simplemente la segunda vez no pasará nada.
He aquí una idea interesante:
~GeoLocalizador() {
LiberarRecursos();
}
public void LiberarRecursos() {
if (_manejadorSistema != null) {
InvocarLiberación(ref _manejadorSistema);
_manejadorSistema = null;
}
}
Pues sí, parece lógico: el finalizador llamará a LiberarRecursos, así que ya tenemos implementada una liberación determinista y una no determinista.
Disponer objetos en .NET
La liberación determinista en .NET tiene un nombre en particular: disponer de un objeto (en inglés, to dispose an object). Y dado que .NET al final engloba muchas de las características del sistema operativo (Windows), es lógico ver que muchos componentes necesitan liberación determinista. Y por tanto es lógico suponer que hay alguna forma estándar de hacerlo.
En efecto, .NET tiene una interfaz muy muy muy importante: IDisposable. Esta interfaz implementa un método Dispose. Este método tiene la misma finalidad que el método LiberarRecursos que nos inventamos hace rato. Así, de esta forma en .NET se estandariza la liberación determinista. Podemos cambiar la clase para adaptarnos.
class GeoLocalizador : IDisposable
{
private IntPtr _manejadorSistema;
public GeoLocalizador() {
_manejadorSistema = InvocarApiDeSistema();
}
~GeoLocalizador() {
Dispose();
}
public void Dispose() {
if (_manejadorSistema != null) {
InvocarLiberación(ref _manejadorSistema);
_manejadorSistema = null;
}
}
...
}
Ahora sí, tenemos una regla a seguir: siempre siempre sieeeeeeeeeeeempre que veas que una clase en .NET implementa la interfaz IDisposable, lo más probable es que se pretenda que los recursos se liberen de forma determinista. Si tienes un objeto así, cuando ya no necesites el objeto, manda llamar a Dispose. Hazlo así muchcahón / muchachona, y evitarás tener fugas de memoria.
Nota: algunas clases implementan IDisposable, y por su naturaleza, también implementan un método Close. Semánticamente, Close puede significar lo mismo que Dispose (por ejemplo, el cerrar una conexión a base de datos implica liberar los recursos también). Por lo que los métodos Close suelen llamar al Dispose. No pasa nada si primero llamas a Close y luego a Dispose, pero bueno, no es necesario hacer la doble llamada de hecho.
Esto nos presenta un dilema interesante. Supongamos que nuestro método CalculaPosicion puede lanzar un InvalidOperationException cuando el localizador no pueda conectarse al satélite o no pueda hacer una triangulación por WiFi o por cualquier motivo. Entonces corremos el riesgo que el Dispose no se invoque. Pero eso lo podemos solucionar con un buen try-finally o try-catch-finally.
GeoLocalizador loc = null;
try {
loc = new GeoLocalizador();
…
} finally {
if (loc != null)
loc.Dispose();
}
Nota que para usar esta construcción, tienes que declarar la variable fuera del try-finally.
Los bloques try-catch-finally me gustan, de hecho, pero hay veces en que es medio tedioso hacer esto. Digo, el try-finally es entendible cuando hay un catch de por medio. Pero si no hay catch, puro try-fianlly, parece una construcción muy grande nada más para liberar un recurso. Pues bien, C# tiene un poco de azúcar sintáctica para nosotros: la sentencia using.
Esta sentencia tiene la siguiente forma:
using (declaración = asignación)
{
// código aquí
}
Dentro del using debe haber una variable, la cual puede estar seguida de una asignación o no. El tipo de dicha variable DEBE implementar la interfaz IDisposable. Si no lo hace, tendrás un error de compilación (i.e. using (int i = 42) { } generará error de compilación). Luego, entre las llaves se pone el código que utiliza la variable en cuestión. Lo interesante sucede cuando alcanzamos la llave de cierre: en ese momento el compilador, tras bambalinas, ¡INVOCA al método Dispose! Precisamente por eso es que el tipo de la variable debe implementar IDisposable. Veamos como quedaría nuestro ejemplo:
using (GeoLocalizador loc = new GeoLocalizacion())
{
loc.CalcularPosicion();
_longText.Text = loc.Longitud.ToString();
_latText.Text = loc.Latitud.ToString();
} // loc.Dispose() llamado tras bambalinas
// aquí loc ya no está disponible
Si estamos seguro que el constructor no lanza excepción, podemos hacerle así:
GeoLocalizador loc = new GeoLocalizacion();
using (loc)
{
loc.CalcularPosicion();
_longText.Text = loc.Longitud.ToString();
_latText.Text = loc.Latitud.ToString();
} // loc.Dispose() llamado tras bambalinas
loc.CalcularPosicion(); // ¡aquí ya lanza una excepción!
Por cierto, en CalcularPosicion pusimos que se lanzara un InvalidOperationException si ya habíamos depuesto el objeto, ¿verdad? Hay una excepción mejor: ObjectDisposedException.
public void CalcularPosicion() {
if (_manejadorSistema == null)
throw new ObjectDisposedException();
… // etc
}
Probablemente también sea mejor cambiar la condición y llevar una variable interna, bool _disposed, que indique si el objeto ya fue depuesto o no. Pero bueno, ya dependerá de ti cómo manejar el estado de tu objeto.
Liberando recursos en objetos compuestos
Hasta ahora hemos visto cómo liberar recursos no administrados vía el destructor, y cómo forzar liberación de recursos vía el método IDisposable.Dispose. Ya vimos también que es una buena práctica que cada que creemos un objeto que implemente IDisposable, invoquemos su método Dispose una vez que dejemos de utilizarlo. Eso está bien cuando creamos objetos en un bloque de código como un método. Pero ¿qué pasa si son miembros de otra clase?
Para ilustrar esto, imaginemos que crearemos una clase llamada Mapa. Esta clase tiene un miembro: GeoLocalizador, a partir del cual pinta la ubicación actual de la persona en el mapa. Asumamos que la clase Mapa tiene que cargar imágenes como recursos no administrados, aprovechando recursos del sistema operativo. Esta clase podría lucir similar a esta.
class Map : IDisposable
{
private GeoLocalizador _loc; // recurso administrado
private IntPtr _mapaBits; // recurso no administrado
public Map() {
_loc = new GeoLocalizador();
_mapaBits = InvocarApiDeSistema();
}
~Map() {
???
}
public void Dispose() {
???
}
…
}
Aquí el punto es importante. Tenemos un miembro administrado y uno no administrado. Sí, _loc es administrado desde el punto de vista de Map, puesto que es una clase de .NET. El colector de basura reclamará a _loc en algún momento y ésta liberará recursos, por tanto se considera que es un recurso administrado. ¿Cómo implementamos Dispose en este caso?
Pues bien, primero pensemos en el recurso no administrado. Éste tiene que estar en el finalizador para asegurar que de una u otra forma se liberen los recursos. Ahora bien, la liberación del recurso administrado no tiene sentido hacerse en el finalizador. ¿Por qué? Pues porque puede ser que para cuando se invoque el finalizador ya se haya liberado el objeto GeoLocalizador. Recordemos que los destructores son no determinados y por tanto asíncronos, así que no podemos hacer esto:
~Map() {
LiberarMapaBitsApi(ref _mapaBits);
_loc.Dispose(); // en la mauser
}
Eso nos da en la torre, pues si _loc ya fue liberado, no podemos invocar _loc.Dispose toda vez que el objeto ya no existe. Por tanto, regla del mundo: en el finalizador, nunca intentes liberar recursos administrados.
Sin embargo, para la liberación determinista de Map, debemos invocar necesariamente a _loc.Dispose. Esto nos lleva al siguiente dilema: el destructor debería invocar a Dispose para liberar recursos no administrados, y la invocación directa de Dispose debería liberar tanto recursos administrados como no administrados. Es decir, tenemos que diferenciar cuándo estamos liberando de forma determinista y cuando no. Esto podemos hacerlo de esta forma: creamos un método Dispose(bool) protegido, al cuál le pasamos una variable: bool indica que estamos liberando de forma determinsta y por tanto liberamos recursos administrados y no administrados. Un false indica que estamos liberando de forma no determinista, y por tanto sólo liberamos recursos no administrados. Entonces sí: desde Dispose(), invocamos a Dispose(true), y desde el destructor, invocamos a Dispose(false).
class Map : IDisposable
{
private GeoLocalizador _loc; // recurso administrado
private IntPtr _mapaBits; // recurso no administrado
public Map() {
_loc = new GeoLocalizador();
_mapaBits = InvocarApiDeSistema();
}
~Map() {
Dispose(false);
}
public void Dispose() {
Dispose(true);
}
protected virtual void Dispose(bool isDeterministic)
{
if (isDeterministic) {
_loc.Dispose();
}
LiberarMapaBitsApi(ref _mapaBits);
_loc = null;
_mapaBits = null;
}
…
}
¡¡Braaaaaaaaavo!! ¡Qué inteligente eres Fernando, guaaaau! Ajem… bueno, a decir verdad… esto que hemos hecho es en realidad un patrón de diseño. Ya sabes, como el singleton o el factory. Es un patrón de diseño de .NET, y se llama "Disposable Object Pattern". Es en realidad un patrón de diseño muy utilizado, y es la forma en la que Microsoft recomienda que se gestionen recursos administrados y no administrados.
Por supuesto, esta es una versión incompleta. Hay algunas cosas que decir. En primer lugar, para el nombre de variable yo emplee isDeterministic. Esto, para mantenerlo en concordancia con los términos que hemos utilizado. En la literatura de .NET, sin embargo, suelen utilizar otro nombre: disposing, queriendo decir que disposing == true significa que el método Dispose fue invocado. En fin, por supuesto puedes ponerle el nombre que quieras a la variable, no importa.
En segundo lugar, omitimos en el ejemplo el marcar que el objeto ya ha sido depuesto. Esto es muy importante, no lo olvides: un objeto que ha sido depuesto debe quedar en estado inválido y no debe poder volver a utilizarse. Es la convención, por supuesto. Puedes ir contra ella, pero le estarías dando al traste con la semántica de IDisposable.
Otra cuestión importante: un método Dispose debería ser posible llamarse en varias ocasiones. La implementación debería ser consciente de esto, y NO LANZAR EXCEPCIONES. Por favor. No lances excepciones desde un destructor. No lances excepciones desde el método Dispose. Es buena práctica y sentido común. Esto nos da una razón más para llevar el control sobre si el recurso ha sido liberado o no. ¡Ala pues!
class Map : IDisposable
{
private GeoLocalizador _loc;
private IntPtr _mapaBits;
private bool _disposed;
private Size _size;
public Map() {
_loc = new GeoLocalizador();
_mapaBits = InvocarApiDeSistema();
_disposed = false; // naturalmente…
...
}
~Map() {
Dispose(false);
}
public void Dispose() {
Dispose(true);
GC.SupressFinalize(this); // ¿¡¿y ahora?!?
}
protected virtual void Dispose(bool isDeterministic)
{
if (!_disposed) {
if (isDeterministic) {
_loc.Dispose();
}
LiberarMapaBitsApi(ref _mapaBits);
_loc = null;
_mapaBits = null;
_disposed = true;
}
// si ya fue depuesto, no hacemos nada.
}
private void EnsureDisposed()
{
if (_disposed)
throw new ObjectDisposedException();
}
public Size Size
{
get {
EnsureDisposed();
return _size;
}
set {
EnsureDisposed();
_size = value;
}
}
public void DrawMap()
{
EnsureDisposed();
… // etc
}
…
}
Bien, podemos ver que creamos una variable _disposed que indica si el objeto ha sido depuesto o no. En nuestro método Dispose(bool), revisamos el valor de esta variable para determinar si liberamos los recursos o no. Si no los liberamos (i.e. _disposed == true) simplemente no hacemos nada, en lugar de lanzar una excepción. Sin embargo, en cualquier otra propiedad o método, revisamos si _disposed es true. De serlo, entonces lanzamos un ObjectDisposedException. Así dejamos súper claro que el objeto ya no sirve.
Por último, vemos que en el método Dispose(), tras la llamada al método interno Dispose(bool), hemos puesto una sentencia que no habíamos visto antes: GC.SupressFinalize. ¿De qué se trata?
En realidad es una forma de mejorar el rendimiento (performance) de la aplicación. System.GC es en realidad una clase que se encarga de exponer algunos métodos estáticos para que podamos dar ciertas instrucciones al colector de basura (GC == Garbage Collector). SupressFinalize es uno de sus métodos, que tiene un parámetro de tipo object. Invocar a ese método es decirle al colector de basura que cuando reclame la memoria del objeto que se pasa como parámetro, ya no se invoque al finalizador (destructor, método Finalize). En este caso, el destructor invoca a Dispose(false). Pero Dispose invoca a Dispose(true), por lo que si ya se liberaron los recursos, no tiene caso que se invoque a Dispose(false) de nueva cuenta. Entonces por eso le decimos al colector de basura que ya ni se moleste. Esto mejorará el rendimiento de la aplicación un poco, porque como hemos dicho, la invocación de finalizadores puede ser costosa.
Naturalmente hay que tener cuidado y no invocar a lo güey SupressFinalize, pues es fácil provocar problemas.
GeoLocalizador loc = new GeoLocalizador(); GC.SupressFianlize(loc); // fuga de memoria asegurada
So say we all
Sean dichas unas últimas palabras antes de cerrar esta entrada. De verdad ten mucho cuidado con la liberación de recursos. En repetidas ocasiones me he topado con programadores que no se preocupan por los recursos, pues .NET los libera. Y claro, cuando liberas una aplicación para 10,000 usuarios y 100,000 transacciones, nos preguntamos por qué está tan lenta. O una aplicación web, nos preguntamos por qué se consume tanta memoria. De verdad, te salvará muchos problemas. Cuando entrevisto programadores, es una de las preguntas que hago, y si no la contestan bien, no continúan. Ya he tenido suficientes problemas por ello como para hacerlo así.
So say we all.
C# 101: símbolos de depuración
En un proyecto estándar generado por Visual Studio, existen dos tipos de configuraciones básicas: Debug y Release. La primera, Debug, suele definir opciones que permiten al compilador generar información sobre el programa: variables, información sobre objetos y clases, etc. Esta información la solemos referir como símbolos de depuración.
Generar los símbolos de depuración son necesarios, pues los depuradores los leen para poder presentar la información al programador durante, digamos, un breakpoint. El programa compila a código binario (o MSIL, en el caso de .NET) y por tanto es imposible saber si quiera el nombre de las variables. Los símbolos de depuración ayudan al depurador con esto. Incluso, esta información permite realizar enlazado de objetos incrementales, reduciendo considerablemente el tiempo de compilación y generación del ensamblado.
Ahora bien, todos los símbolos de depuración se almacenan en una base de datos, llamada Program Database (PDB). Este archivillo, que puedes encontrar en el directorio de salida con la extensión PDB, es de hecho una base de datos que puede ser abierta con el motor SQL Server Compact Edition (i.e. puedes usar el SQL Server Management Studio).
El depurador, que es quien usa el PDB, lo carga al momento de iniciar una sesión. Lo busca en el directorio donde se encuentra el EXE. La parte importante es que el depurador revisa que coincida, a nivel binario, todo lo que dice el PDB con el ejecutable mismo. Si no coinciden, el PDB no es cargado. Si el PDB no existe, el Visual Studio nos presenta una ventana para que escojamos el directorio donde se encuentra. Esto último es importante, pues nos permite cargar símbolos que se encuentren en otras ubicaciones.
Hay un escenario en particular donde esto es útil, y lo ilustraré con una anécdota personal. Cuando desarrollamos nuestras aplicaciones, usualmente llega el momento de pasarlas a algún servidor de Q&A, antes del Go Live. Ahí, los clientes suelen realizar sus pruebas. En esta ocasión, el sistema estuvo jalando bastante bien, hasta que en una ocasión un usuario logró hacer tronar la aplicación bajo ciertas condiciones. Rápidamente nos reportó el problema.
Pues resultó que no pudimos duplicar el problema en nuestro ambiente de desarrollo. Estuvimos tres días intentándolo, copiando las características del servidor de Q&A. Nada. Funcionaba a la perfección. Hasta intentamos ver que el problema no estuviera "entre la silla y el teclado". Nada. Los logs y traces de poca ayuda fueron.
Desafortunadamente, la fecha para la liberación del sistema se acercaba peligrosamente, así que no nos quedó de otra: solicitamos permiso para instalar el Visual Studio en el servidor de Q&A para de ahí ejecutar el programa y ver qué sucedía. Naturalmente, nos mandaron a freír espárragos: no sólo necesitaban autorización del corporativo, la cuál tardaría mínimo un mes, sino que no estaba permitido instalar programas en los servidores de Q&A, y que el hacerlo provocaría que nos impidieran el paso a producción, pues ellos no podrían certificar que la app funcionara bien.
En fin, tras varias reuniones y alegatos, propusimos que se hiciera todo de forma remota: a final de cuentas, el Visual Studio podía conectarse de forma remota. Sin embargo, les dijimos, necesitamos que coloquen el archivo PDB… y ardió Troya: que no, no se podía alterar el ambiente de Q&A, yada yada yada. En fin, terminamos generando el PDB y gracias a esta opción de seleccionar el archivo, pudimos conectarnos de forma remota con el PDB en nuestro equipo local. De esta forma encontramos que era el Directorio Activo quien daba un timeout, y pudimos solucionar el problema.
Un truco antes de partir
Bueno, esta entrada ha sido más informativa que otra cosa. Pero voy a dejar un pequeño truco antes de concluirlo, para que no te vayas en cero.
Cuando depuramos un programa, podemos ver el valor de las variables de tipo de dato en las ventanas de Quick Watch del Visual Studio.

Ahora bien, esto funciona padre para tipos de datos simples como int, bool o string. ¿Qué pasa con tipos de datos complejos, como un DataTable? ¿Qué pasa con las clases que nosotros creamos?
Si ves la imagen anterior, en el caso del DataTable muestra este valor: {Length=1}. Es decir, que el DataTable explícitamente indica que el valor que interesa es el valor de la propiedad Length. ¿Cómo puedo hacer esto para mis clases?
Este es el truco: para hacer esto, tenemos que utilizar la clase DebuggerDisplayAttribute, en el espacio de nombres System.Diagnostics. En este atributo, al constructor le pasamos una cadena de texto con un formato sobre cómo va a mostrarse el valor. Por ejemplo:
[DebuggerDisplay("Length = {Length}")]
class MyClass
{
public int Length { get; set; }
}
Y eso es suficiente. Con esto, aparecerá una cadena de texto donde el texto entre llaves se reemplaza por el valor del elemento: miembro o propiedad, cuyo nombre corresponda con el nombre entre las llaves.
Y este es el truco. Puedes revisar la documentación de DebuggerDisplayAttribute para mayor información.
C# 101: directivas de preprocesador
Recuerdo mi época de programador de C++. No fue hace mucho, mi última aplicación la terminé hace unas tres semanas. Quizás debí decir: "recuerdo cuando comenzaba a programar en C++", y entonces sí nos vamos 10 años atrás… En fin, como sea. En C y C++, uno podía ver código como este:
#ifdef _WIN32 #ifdef UNICODE #define _tcscpy wcscpy #elif #define _tcscpy strcpy #endif #endif
Todas las directivas que comienzan con un gato (singo de libra, de número o como se llame en tu villa) son directivas de pre-procesamiento. Esto quiere decir que hay un software antes que el compilador, que básicamente sustituye los símbolos (llamados macro) por otros, es decir, los pre-procesa. En el caso anterior, cualquier llamada a _tcscpy se sustituido por wcscpy o por strcpy, dependiendo de si el símbolo _WIN32 y el símbolo UNICODE están definidos.
En fin, en C# también tenemos directivas de pre-procesamiento, aunque en realidad es el mismo compilador. A diferencia de C y C++, no pueden crearse macros. Pero sí se puede utilizar para crear compilaciones condicionales, que nos ayudan a generar diferentes ensamblados.
Definición de símbolos
Las primeras directivas que veremos son las directivas para definir símbolos. Estas son #define y #undef. A diferencia de C y C++, #define no asigna valor a una macro, sino que simplemente define el símbolo. Éste podrá ser utilizado después, pero hasta ahí.
#define DEBUG
public void TraceDebugInfo()
{
}
#undef DEBUG
En el ejemplo anterior, definimos el símbolo DEBUG, y luego lo indefinimos. Estas directivas no son muy útiles por sí mismas, pero se convierten en útiles cuando las combinamos con directivas de decisión.
Definir un símbolo con #define es equivalente a definir un símbolo al momento de compilar mediante el parámetro /define.
Decisión de compilación
La decisión de compilación significa que una porción determinada de código se compila si se cumple una condición en particular. La condición que debe cumplirse es si un símbolo está definido o no. Pueden concatenarse símbolos con los operadores lógicos &&, || y !, pero a eso se limita. Ahora sí hace más sentido el #define, ¿no?
public void Trace(string msg)
{
#if DEBUG && ENABLE_TRACE
Debug.WriteLine(msg);
#elif !DEBUG && ENABLE_TRACE
File.WriteAllText("C:\\log\\debug.log", msg);
#else
Console.WriteLine(msg);
#endif
}
#if es la directiva para evaluar un símbolo. Si la expresión se evalúa a true, todo lo que haya después y hasta alguna otra directiva complementaria, se compila. Si no, no. Tanto #else como #elif se usan como alternativas, pero #elif permite poner una expresión a evaluar, mientras que #else no. Finalmente, el bloque debe cerrarse con un #endif.
En el ejemplo anterior, si compilamos con /define:DEBUG /define:ENABLE_TRACE, el mensaje se imprimirá en la consola de depuración (útil sólo cuando depuramos desde Visual Studio). Si compilamos con /define:ENABLE_TRACE solito, escribimos todo a un archivo de texto. Si no definimos ENABLE_TRACE, entonces escribimos en la consola de la aplicación. Por supuesto, en lugar de la compilación con /define, podemos usar #define.
Hemos hablado de cómo compilar con /define para definir símbolos, y por tanto utilizar las directivas #if, #elif, #else, #endif. Realmente así es como hace sentido, pues hacer los #defines no siempre es muy práctico, pues un cambio implica modificar el código fuente.
Visual Studio incluye un componente llamado Configuration Management. Este componente permite definir construcciones (builds). Cada construcción define qué ensamblados va a compilar, qué ensamblados referenciar, y otras configuraciones de compilación, etc. De hecho, por defecto, el Visual Studio nos genera un par de construcciones: Debug y Release. Si comparas ambas, verás que Debug tiene opciones de depuración habilitadas, que no suelen ser necesarias en la versión de producción.
Pues bien, entre las cosas que nos permite configurar están precisamente los símbolos con los que queremos compilar. En las propiedades del proyecto, tab Build, nos aparecen las configuraciones existentes. Abajo, aparece "Conditional combination symbols", ahí podemos escribir los símbolos que queramos definir. Adicionalmente, tenemos dos opciones: definir la constante DEBUG, que ya conocimos, y la constante TRACE.
![clip_image001[4]](https://fermasmas.files.wordpress.com/2012/11/clip_image0014.png "clip_image001[4]")
Adicional a las construcciones predefinidas, podemos crear las nuestras personalizadas. Quizás queremos establecer símbolos para diferentes plataformas (Windows, Silverlight, 32 vs 64 bits, etc.). Para crearlas, seguimos estos pasos.
1.- Seleccionar la solución o proyecto en el Solution Explorer.
2.- Seleccionar el menú Build y escoger la opción Configuration Manager.
3.- En Active Solution Configuration, seleccionamos la opción "<New>". Con esto nos pedirá el nombre y si queremos basarnos en alguna configuración. Terminando, hacemos clic en OK.
4.- Una vez creada, ya podemos cambiar la configuración que hemos creado.
Más información sobre este tema:
1.- how to: create and edit configurations.
2.- how to: modify project properties and configuration settings
Advertencias y errores
A veces querremos indicar alguna condición bajo la cuál queramos lanzar una advertencia o algún error. Por ejemplo, supongamos que todavía no hemos probado el código en modo de depuración. Entonces queremos lanzar una advertencia al compilar.
#if !DEBUG #warning No hemos probado este código en modo Release. ¡Aguas! #endif
O por ejemplo, nuestro código no va a soportar aplicaciones de 32 bits para Windows NT. Podemos definir símbolos con /define: para Windows NT.
#if WINNT && PLATFORM_x86 #error No se soporta WINNT en 32 bits. #endif
Vemos que se usa #warning y #error para ello, seguido del mensaje que queramos mostrar.
Por otro lado, tenemos que el compilador de C# genera muchas advertencias. Esto, independientemente de los errores, por supuesto. El compilador tiene diferentes niveles de advertencias, y la finalidad de éstas consiste en que los programadores reciban recordatorios sobre potenciales problemas detectados en código, o posibles omisiones. Considera este método:
void foo()
{
int i = 0;
throw new Exception();
goo();
}
Este código genera dos advertencias. En primer lugar, nos dice que la variable i es inicializada pero nunca utilizada. Lo cual tiene sentido: ¿para qué declarar una variable si nunca la utilizas? Por otra parte, también nos da otra advertencia: el método foo tiene código inaccesible que nunca se ejecuta. En efecto, dado que el throw hace que la función termine anticipadamente, goo nunca será ejecutada. De ahí la advertencia.
Usualmente las advertencias deben ser corregidas. Pero en dado caso de que el código que provoca la advertencia sea intencional, entonces podemos deshabilitar la advertencia para que el compilador no la muestre. Para ello usamos la directiva #pragma warning disable, seguida del número de advertencia que queremos deshabilitar.
class Base
{
public virtual void foo() { }
}
class Derivada : Base
{
#pragma warning disable 0108
// 'member1' hides inherited member 'member2'. Use the new keyword
// if hiding was intended.
public void foo()
#pragma warning enable 0108
}
Vemos también que las advertencias pueden ser habilitadas de nuevo usando el #pragma warning enable, seguido del número de advertencia.
Regiones
En C# podemos crear regiones de código y asignarles una descripción. Esto lo logramos mediante las directivas #region y #endregion.
class Employee
{
#region Atributos
private int _id;
private string _name;
private double _income;
#endregion
#region Propiedades
public int ID { … }
public string Name { … }
public double Income { … }
#endregion
#region Métodos
public void CalcIncome(DateTime from, DateTime until) { … }
public override string ToString() { … }
#endregion
}
Esta es una forma de utilizarse. La verdad es que desde aquí no se ve que haga nada. Y de hecho no hacen nada: las regiones sirven para dividir el código, pero no afecta al compilador. De hecho sólo tienen utilidad dentro de Visual Studio. El Visual Studio permitirá expandir y contraer regiones, haciendo más fácil la navegación en el IDE.
Misceláneos
Existen un par de directivas misceláneas. La directiva #line permite cambiar la línea del código fuente, afectando los mensajes de advertencia y errores de compilación que puedan suceder.
void foo()
{
// CS0429
if (false) {
Console.WriteLine("Foo");
}
}
El código anterior nos muestra lo siguiente, suponiendo que void foo sea la primera línea:
Warning CS0429: Unreachable expression code detected in file ‘File.cs’ line ‘5’
Ahora usemos la directiva #line:
#line 37
void foo()
{
// CS0429
if (false) {
Console.WriteLine("Foo");
}
}
Ahora tenemos:
Warning CS0429: Unreachable expression code detected in file ‘File.cs’ line ’42’
Con #line, movimos el número de línea. Ahora, ¿cómo para qué sirve esto? Ni idea. Pero lo puedes hacer, si quieres sacarle canas blancas al resto de tu equipo de trabajo.
La otra directiva miscelánea es el #pragma checksum. Esta directiva genera "checksums" para un archivo determinado. Un checksum es un número o identificador que se asigna a algún elemento, para comprobar que se esté utilizando la última versión. En particular, esto es útil para págians de ASP.NET, ya que los ASPX están separados de los ensamblados.
Este es un ejemplo:
#pragma checksum "file.cs" "{3673e4ca-6098-4ec1-890f-8fceb2a794a2}"
"{012345678AB}"
That’s that!
Pues eso es todo. Esas son todas las directivas de preprocesador existentes en C# hasta la versión actual. Ciertamente la parte importante es #if / #endif y #define. Se les puede sacar mucho provecho. Sin embargo, no hay que abusar: un error común que no queremos heredar de C y C++ es precisamente el llenarnos de directivas.
